
Exploring GPT3 - Best Way to Use GPT3 for Data Labeling (aka Data Annotation)
How to use GPT-3 for data labeling aka data annotation?


In the previous blog post, you have seen how to leverage GPT-3 model for data labeling in different ways. In this blog post, you are going to see how to further improve the quality of labels assigned by the GPT-3 model.
🎖 For all the latest updates in AI and Data Science, subscribe to my free AI Newsletter
🌴Why can't we directly use GPT-3 model for inference?
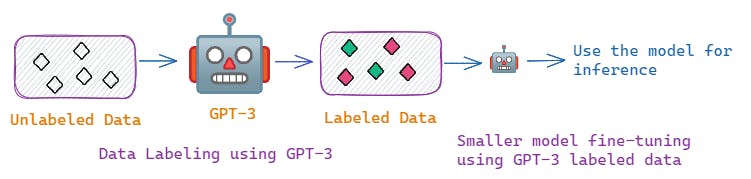
As shown in the above figure, initially unlabeled data is labeled by GPT-3 model. Using the GPT-3 labeled data, smaller models like BERT, RoBERTa etc., ( for NLU tasks), T5, BART, PEGASUS etc.,(for NLG tasks) are fine-tuned and then used for inference. A simple question that can pop up in your mind is
🎈 Why can't we directly use GPT-3 model for inference?
This question is very much reasonable and convincing. This is because, if you use GPT-3 model directly for inference, the following two steps can be avoided
Data labeling using GPT-3
Fine-tuning the smaller models
When it is pretty straightforward to use GPT-3 model for inference owing to its very good performance in many NLP tasks in few-shot settings [1,2,8], why NLP research community is exploring GPT-3 model for data annotation? Here are the reasons
Commercial Access - GPT-3 is not publicly available to access i.e., you have to pay to access GPT-3. The cost of using GPT-3 increases linearly with the number of instances it handles during inference.
High Latency - GPT-3 is a very large model with 175B parameters. Such a large model will have relatively high latency.
These two reasons forced NLP researchers to explore GPT-3 as a data annotation tool. With GPT-3 labeled data, smaller models like BERT, RoBERTa, T5, PEGASUS can be trained and deployed for real-world applications. The advantages of fine-tuning and using these smaller models are
Free Access - Models like BERT, RoBERTa, T5, and PEGASUS are freely accessible so you need not pay for their access.
Low Latency - As these models are much smaller in size compared to the giant 175-B GPT-3 model, these models have relatively low latency. Moreover, the latency of these models can be further reduced using various techniques like knowledge distillation, quantization, pruning and ONNX Runtime.
Now, one more question will pop up in your mind.
🎈 Are these smaller models trained on GPT-3 labeled data perform on par with GPT-3 model?
The answer is yes. The smaller models trained on GPT-3 labeled data outperform GPT-3 model in the few-shot setting for both NLU and NLG tasks [1]. Now let us see how to further improve the quality of GPT-3 labeled data.
🌴Data Labeling Approaches
In general, data labeling approaches can be broadly classified into Human-based, Machine and Hybrid. Now you are going to see four different data labeling approaches namely
Human Labeling
GPT-3 Labeling
GPT-3 + Human Labeling
GPT-3 + Human Active Labeling
Out of these four approaches, GPT-3 labeling approach comes under the machine category and GPT-3 +Human, GPT-3+Human Active approaches come under the hybrid category as both these approaches leverage both machine and human annotators.
🌹Human Labeling
As the name indicates, this approach involves human experts labeling the data. The first step is to hire human experts, train them (explain the guidelines for data labeling) and then the trained human experts label the data.
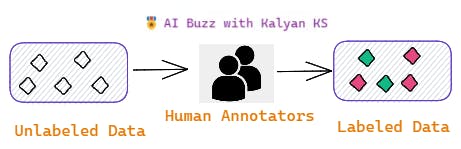
Now let us see the pros and cons of human labeling
Pros
- High-quality data labels. Out of all the labeling approaches, human-assigned labels are comparatively of high quality.
Cons
Expensive
Time Consuming
🌹GPT-3 Labeling
As human labeling is expensive and time-consuming, the NLP research community impressed by the performance of the GPT-3 model in the few-shot NLP tasks, started to explore GPT-3 as a cheap data annotation tool. Labeling data using GPT-3 involves inputting the model with a task-specific prompt. There are three different ways to create task-specific prompts [2] namely
Prompt-Guided Unlabeled Data Annotation (PGDA)
Prompt-Guided Training Data Generation (PGDG)
Dictionary Assisted Training Data Generation (DADG)
You have already learned about all these approaches in the previous blog post. In the previous blog post, you have seen that PGDA is the most effective approach. Now you are going to use the PGDA approach to create the prompt.
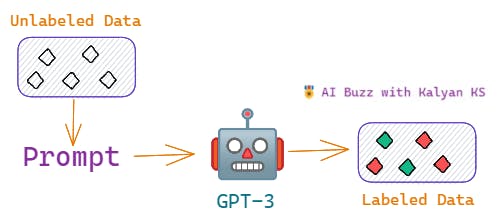
Here the prompt includes task description, in-context labeled instances and the unlabeled instance which is to be labeled.
For example, in the case of sentiment analysis (text classification), the prompt will be something like this

The same prompt format can be used for NLG tasks also.
Here the number of in-context labeled instances has an impact on the quality of labels generated by the GPT-3 model. This is because, with more in-context labeled instances, the model understands the task and the relationship between the instances and the labels better and hence generates more quality labels [1]. In general, when you use 'n' labeled in-context labeled instances, it is referred to as n-shot GPT-3 labeling. GPT-3 usage is charged based on the number of tokens in the prompt and the number of tokens it generates in the output. So, as 'n' increases, the number of tokens also increases which eventually increases the cost of data labeling . So, the 'n' value has to be chosen according to the budget.
Pros
Less expensive compared to human labeling
Fast compared to human labeling
Cons
- Compared to the quality of human labels, the quality of GPT-3 labels is less.
🌹GPT-3 + Human Labeling
In the previous two data labeling approaches, the source of labels is only one i.e., either a human expert or a machine (GPT-3).
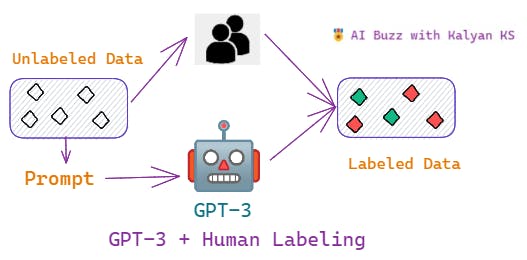
In this approach, the labels are derived from two sources namely human expert and machine (GPT-3). The unlabeled data is splitted into two parts, given to human annotators, and to machine (GPT-3) for labeling. The ratio in which the unlabeled data is divided depends on the budget. If the available budget is more, then more data is labeled by the human expert otherwise, more data is labeled by the machine. Once the data is divided and labeled by human & machine, the smaller model is trained based on the following loss function (L)
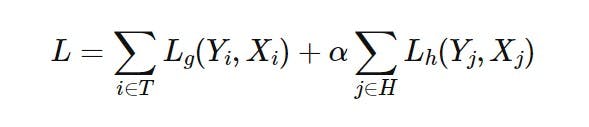
Here T represents the set of instances labeled by GPT-3 and H represents the set of instances labeled by the human expert. As GPT-3 labels are comparatively noisier, the alpha parameter is included to give weight to human-assigned labels. It is a hyperparameter that has to be tuned according to the task. In the paper [1], the authors have tried {1,3} values for alpha hyperparameter.
🌹GPT-3 + Human Active Labeling
In this approach, all the unlabelled instances are labeled by the machine (GPT-3).
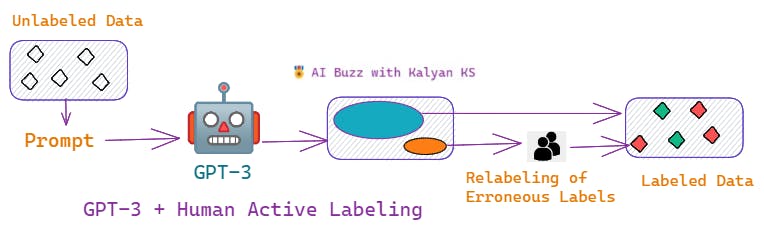
However, compared to human-assigned labels, GPT-3 labels are somewhat noisy i.e., some of the labels are not assigned correctly. If we can identify such erroneous labels, then such instances can be relabeled which improves the overall quality of the labeled data.
💡How to identify erroneous labels?
GPT-3 takes the input prompt and then outputs the desired label along with the logits. These logits can be treated as confidence scores i.e., the labels with low confidence scores are erroneous. Training on such erroneous labels limits the performance of the model.
💡How to relabel the erroneous labels?
As GPT-3 model is less confident about the erroneous labels, these instances can be assigned to human annotators for relabeling. Once these erroneous labels are relabeled, the overall quality of the labeled data improves and the labeled data can be used for training the model.
🌴Which data labeling approach is the best?
Wang et al. [1] conducted a lot of experiments on both NLU and NLG datasets to compare the four data labeling approaches namely (Human Labeling, GPT-3 labeling, GPT3 + Human labeling, GPT3 + Human Active Labeling).
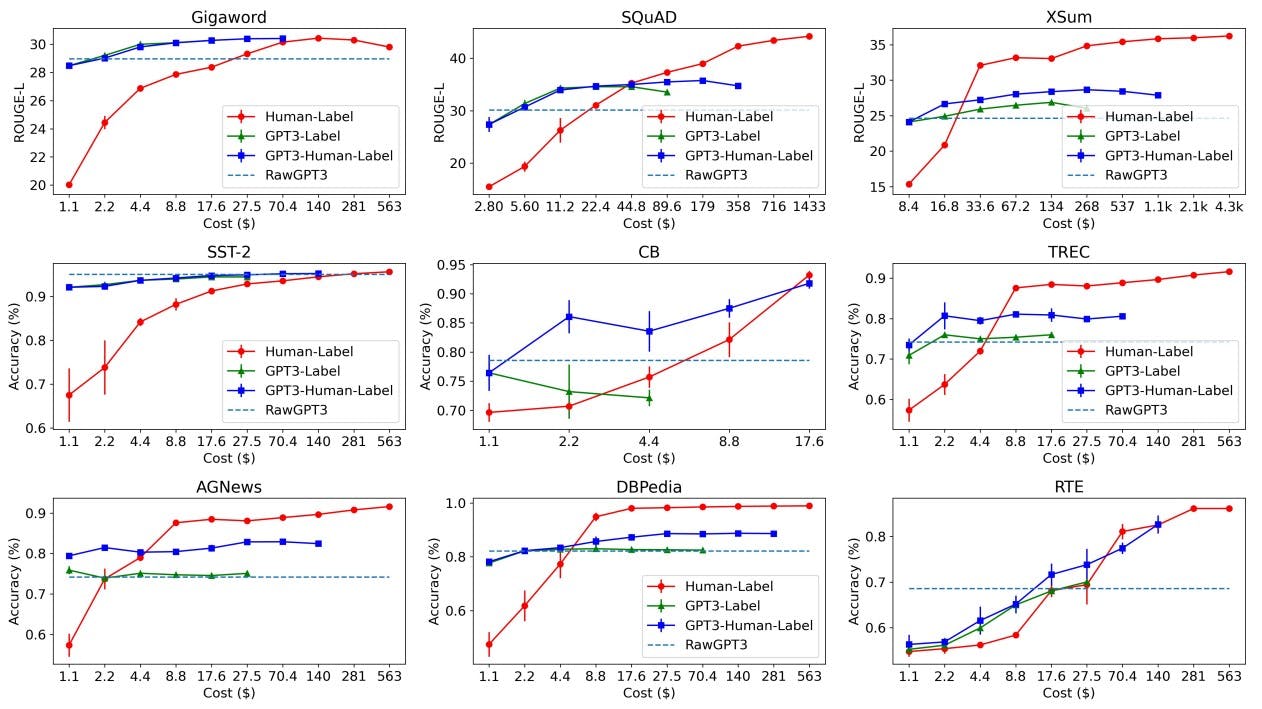
Here GPT3-label represents the performance of the smaller model fine-tuned using the data labeled using GPT3-labeling approach.
Similarly, GPT3-Human label represents the performance of the smaller model fine-tuned on the data labeled using GPT-3 + Human labeling approach. The smaller models used in all the experiments are RoBERTa-Large (for NLU tasks) and PEGASUS-Large (for NLG tasks).
RawGPT3 means GPT-3 model is directly used for inference.
From the above figure, two important points to be noted are
When the budget is small, all the GPT3-based approaches outperform human labeling. This is because, at a low budget, you can only label a few instances using human labeling. With the same small budget, you can label more instances using GPT-3.
In the case of GPT3-based approaches, GPT3+Human label outperforms other approaches. This is because relabeling erroneous instances improves the overall quality of labeled data.
In most of the cases, the smaller models trained on GPT-3 labeled data outperform GPT-3 model itself (horizontal dashed line).
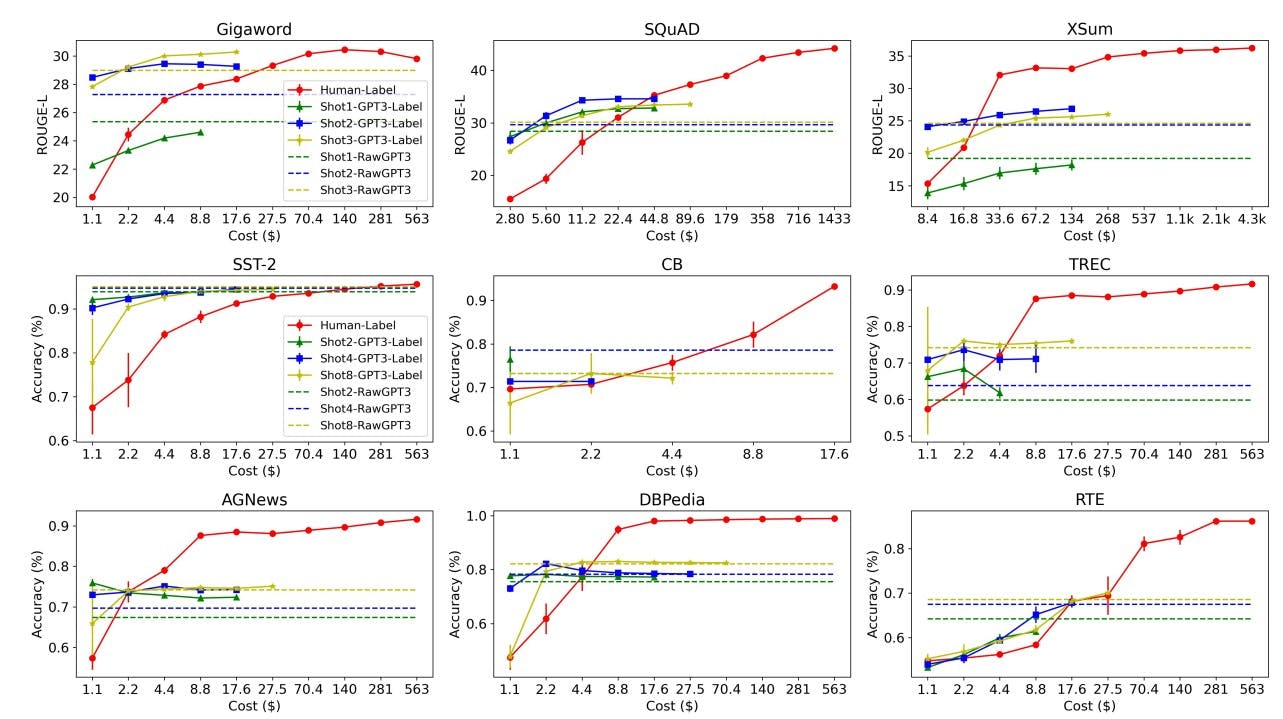
From the above figure, the points to be noted are
When the budget is small, 2-shot GPT3 performs better than higher-shot approaches. This is because higher-shot approaches are more expensive compared to 2-shot which limits the number of instances to be labeled. With the same small budget, you can label comparatively more instances using 2-shot GPT3 approach.
When the budget is increased, higher-shot GPT3 approaches outperform lower-shot GPT3 approaches. This is because more budget allows more instances to be labeled using higher-shot GPT3 approaches.
In most of the cases, the smaller models trained on GPT-3 labeled data outperform GPT-3 model itself (horizontal dashed line).
🌴Summary
Human labeling gives high-quality labeled instances. However as human labeling is expensive, small budgets can't afford to use human labeling to label the entire unlabeled data.
In limited budget scenarios, GPT-3 comes in handy for cost-effective data annotation.
Out of all the GPT-3 based data labeling approaches, GPT-3+Human Active labeling offers comparatively high-quality labeled data.
The Smaller models trained on data labeled using GPT-3+Human Active labeling outperform GPT-3 model itself in few-shot settings.
The number of in-context labeled instances in the input prompt influences the quality of annotated data. The cost of labeling increases with an increase in the number of in-context labeled instances. So there is a trade-off between the number of in-context labeled instances in the prompt and the budget.
🌴Future Research Directions (not available in the paper)
There may be more focus on reducing the number of erroneous labels (low confidence labels) so that the amount of money spent for active labeling component (relabeling erroneous labels) can be reduced.
As GPT-3 model is not free to access, the NLP research community may focus on exploring other models like GPT-JT [3], GPT-NeoX [4] etc. so that the data labeling budget can be significantly reduced.
In 2022, the NLP research community witnessed open-source alternatives to GPT-3 like BLOOM [5] and OPT [6]. These models are free to access and have the same size as GPT-3. So, NLP researchers may explore these models for data labeling.
ChatGPT [7], the recent AI Buzz can also be explored for data labeling.
🎖 For all the latest updates in AI and Data Science, check my free AI Newsletter
🌴References
[1] Wang, S., Liu, Y., Xu, Y., Zhu, C. and Zeng, M., 2021. Want to reduce labeling cost? GPT-3 can help. arXiv preprint arXiv:2108.13487.
[2] Ding, B., Qin, C., Liu, L., Bing, L., Joty, S. and Li, B., 2022. Is GPT-3 a Good Data Annotator?. arXiv preprint arXiv:2212.10450.
[3] https://huggingface.co/togethercomputer/GPT-JT-6B-v1
[4] https://github.com/EleutherAI/gpt-neox/
[5] Scao, T.L., Fan, A., Akiki, C., Pavlick, E., Ilić, S., Hesslow, D., Castagné, R., Luccioni, A.S., Yvon, F., Gallé, M. and Tow, J., 2022. BLOOM: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
[6] Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X.V. and Mihaylov, T., 2022. OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
[7] https://openai.com/blog/chatgpt/
[8] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A. and Agarwal, S., 2020. Language models are few-shot learners. Advances in neural information processing systems, 33, pp.1877-1901.