Pretrained Language Models for Neural Machine Translation
Overview of various pretrained language models for machine translation

🔸I'm Katikapalli Subramanyam Kalyan (shortly Kalyan KS), NLP researcher with over 5 years of research experience.
🔸I have published research papers in top tier journals in medical informatics and EMNLP, AACL-IJCNLP workshops.
🔸My papers on transformers-based pretrained language models received 60+ citations including the citations from papers published by researchers from top tier institutes like University of Oxford, University of Texas, NTU Singapore, IIT Madras and top companies like Google.
🔸I have been serving as program committee member (as reviewer) for the last three years for ML4H workshop organized by researchers from top institutes like Stanford.
🔸 My broad research interests are natural language processing and deep learning. Specifically, I'm interested in pretrained language models and their application in various NLP tasks, learning with limited labeled data, robustness of NLP models and developing libraries for NLP tasks.
Part 1 : Evolution of Neural Machine Translation (NMT) Systems
Part 2 : Pretrained Models for Neural Machine Translation (NMT) Systems
Part 3 : Neural Machine Translation (NMT) using Hugging Face Pipeline
Part 4 : Neural Machine Translation (NMT) using EasyNMT library
Transformer-based Pretrained language models (T-PTLMs) are transformer-based neural network models which are pretrained on large volumes of text data. T-PTLMs can be an encoder, decoder, or encoder-decoder based. Encoder-based models are mostly used for NLU tasks, Decoder-based models are mostly used for NLG tasks, while Encoder-Decoder-based models are mostly used for NLG tasks. As machine translation (MT) is a sequence-to-sequence task, i.e., input is a text sequence, and output is also a text sequence. For MT, we use encoder-decoder-based T-PTLMs. The below figure shows the classification of various T-PTLMs that can be used for MT. From the above figure, we can observe that T-PTLMs for MT can be broadly classified into two categories, namely raw and fine-tuned.
💥 Raw Models
Raw models are the ones that are just pretrained on large volumes of monolingual data but not fine-tuned on any MT-specific dataset. These models can be used for MT after tuning on downstream MT datasets. Without fine-tuning, the performance of these is very limited. Examples of raw models are multilingual pretrained language models like mT5 and mBART-50.
💥 Fine-tuned Models
Fine-tuned models are the multilingual pretrained models which are fine-tuned on MT datasets. As these models are already fine-tuned on MT datasets, the performance of these models is far better when compared to raw models in zero-shot machine translation. Although these models are fine-tuned on MT datasets, the performance of these models on specific MT datasets can be further improved by further fine-tuning on the downstream MT dataset. Examples of these models are OPUS-MT, mBART-OM, mBART-MM, mBART-MO, M2M100 and NLLB200.
💥 Single Direction (SDMT) and Multi Direction (MDMT) Machine Translation Models
These fine-tuned models can be further classified into SDMT and MDMT models. SDMT (Single Direction MT) models are the models which can translate data in only one direction. For example, consider the OPUS-MT model opus-mt-en-de. This model is pretrained on parallel data of English and German languages only. So this model can translate data from English to German i.e., the model can translate the data in one direction only. SDMT models are also referred to as Bilingual Machine Translation models. MDMT (Multi Direction MT) models are the models which can translate the data in more than one direction. For example, mBART50-MO can translate data from any of the supported 49 languages to English. Similarly, mBART50-OM can translate the data from English to any of the supported 49 languages. Similarly, mBART50-MM can translate the data for any pair of languages from the supported 50 languages. MDMT models are also referred to as Multilingual Machine Translation Models.
💥 English and Non-English centric Machine Translation Models
MDMT models can be further classified into English Centric and Non-English Centric.
➡️ English-centric models are models which are pretrained on English-centric parallel data. English-centric parallel data consists of pairs of text sequences in which one text sequence is in English, and the other sequence can be from any of the supported languages. mBART50-based models are examples of English Centric.
The main drawback of English-centric models is their lower performance for non-English translation directions.
➡️ To overcome the drawbacks of English-centric models, non-English-centric models like M2M100 and NLLB200 are developed. The parallel data used to pretrain these models are non-English centric, i.e., one of the sentences in the sentence pair need not be English. Pretraining on non-English centric parallel data helps to model to perform well in non-English translation directions also.
Let us see a brief overview of each of NMT models.
💥 OPUS-MT Models
OPUS-MT are Single Direction MT, or Bilingual MT models developed by the Helsinki-NLP group. As of now, there are more than 1000 OPUS-MT models. Each model is transformer based, with six layers in the encoder and decoder. Each model is trained from scratch using OPUS parallel data. For example, the model Helsinki-NLP/opus-mt-en-de is trained using a corpus having parallel sentences from the English and German languages. Here en in the model name represents English language (source language), and de represents German language (target language).

This model can translate a text sequence in the English language to the German language. OPUS-MT models are initially using trained using C++ based Marin-MT framework and later converted to PyTorch so that these models can be accessed using the transformers library.
💥 mBART-50
mBART-25 is a multilingual encoder-decoder-based pretrained language model developed using denoising autoencoder pretraining objective. In denoising autoencoder pretraining objective, the encoder receives a corrupted input sequence while the decoder auto-regressively generates the original input sequence. mBART-50 is developed by further pretraining mBART-25 on a huge corpus having monolingual data of 50 languages.

mBART-25 is fine-tuned on the bitext corpus (a parallel corpus of one language pair) to develop MT models. However bilingual fine-tuning does not leverage the full capacity of multilingual pretraining. So, multilingual fine-tuning is applied on mBART-50 using ML50 corpus to develop machine translation models like mBART-50-one-to-many-mmt (represented as mBART50-OM), mBART-50-many-to-many-mmt (represented as mBART50-MM), mBART-50-many-to-one-mmt (represented as mBART-MO). ML50 is an English-centric parallel corpus in which each sentence pair of consists of an English sentence and a sentence from any of the 49 other languages.

💥 M2M100
It is the first multilingual machine translation model that can translate between any pair of 100 languages without depending on English-centric parallel data. M2M100 is trained on a non-English-centric corpus consisting of 7.5B sentence pairs in 2200 directions. M2M100 is available in three different sizes, namely M2M100-400M, M2M100-1.2B, and M2M100-12B. All these three models are publicly available and accessible from Huggingface Hub.
💥 NLLB200
NLLB200 is the first machine translation model to translate text data in two hundred languages. The model is pretraining on a large non-English-centric parallel data corpus. NLLB200 is available in four different sizes, namely NLLB200-distilled-600M, NLLB200-distilled-1.3B, NLLB200-1.3B, NLLB200-3.3B. All these models are publicly available and accessible from Huggingface Hub.
💥 Overview of SOTA Machine Translation Models
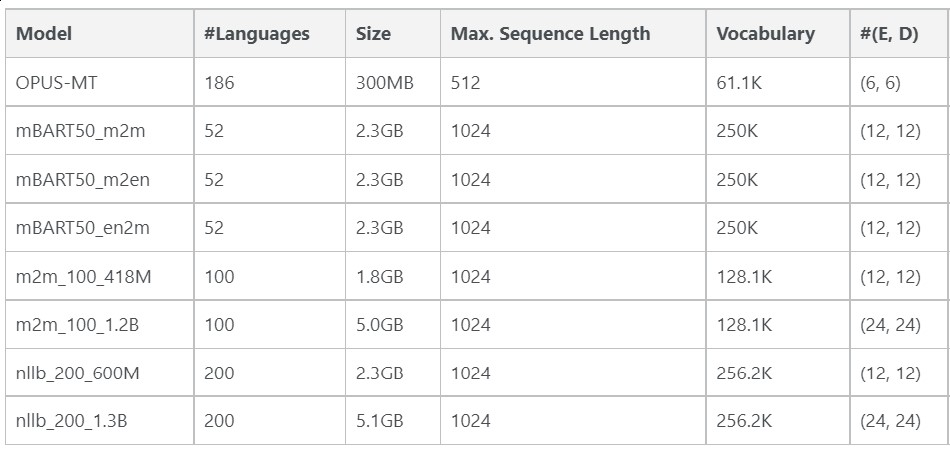
Here is the table which gives a brief overview of various SOTA Machine Translation Models
| Model | Link |
| OPUS-MT | Model |
| mBART50_m2m | Model |
| mBART50_m2en | Model |
| mBART50_en2m | Model |
| m2m100_418M | Model |
| m2m100_1.2B | Model |
| nllb200_600M | Model |
| nllb200_1.3B | Model |
From the table, we can observe the following.
OPUS-MT models are much lighter compared to all other SOTA models.
NLLB200 models have the largest vocabulary of 256.2K. These models have a large vocabulary as they have to accommodate 200 languages.
NLLB models can support machine translation for 200 languages.




